Statistiques/Généralités
Étude des caractères quantitatif
Les statistiques, c'est quoi ?
modifierLa statistique est une branche des mathématiques appliquées qui a pour objet l'étude des phénomènes mettant en jeu un grand nombre d'éléments. Les statistiques désignent un ensemble de données numériques concernant l'état ou l'évolution d'un phénomène que l'on étudie par la statistique.
La statistique ne se contente pas de décrire un ensemble d'observations (statistique descriptive), elle s'efforce également de les interpréter pour aboutir à une prévision ou une décision (statistique inductive). Elle cherche en quelque sorte à maîtriser le hasard.
L'étude statistique
modifierL'étude statistique d'un phénomène donné se décompose en quatre phases :
- L'objet de l'étude : il est indispensable de définir l'objet de l'étude, la population étudiée, le nombre d'observations nécessaires, les méthodes à utiliser pour recueillir les données ...
- La collecte des données : il s'agit de collecter tous les renseignements sur les faits à observer ; deux méthodes sont utilisées :
- La collecte exhaustive, c'est-à-dire celle qui concerne tous les éléments du champs d'observation. On parle aussi de recensement.
- La collecte partielle, dans le cas où l'on n'a pas les moyens de prospecter tout le domaine d'observation, on effectue un échantillonnage. Ce type de collecte nécessite une stratégie particulière pour que l'échantillon soit convenablement représentatif de la totalité du domaine.
- Le dépouillement : il faut ordonner les données recueillies, tout en éliminant celles qui sont suspectes ou illogiques.
- La présentation et l'exploitation.
La statistique descriptive
modifierLa statistique descriptive a pour but d'analyser les données, de les ordonner et de dégager certaines caractéristiques du domaine observé.
Par définition, l'analyse statistique s'effectue sur un nombre d'individus xi appelés unités statistiques qui forment un ensemble appelé population (P). L'emploi de ces mots se réfère au vocabulaire de la démographie. On note généralement :


Les unités sont supposées distinctes les unes des autres en fonction d'un ou de plusieurs caractères.
Exemple : parmi la population d'employés d'une entreprise, on peut considérer pour chacun d'eux : l'âge, le sexe, le salaire, le nombre d'heures de travail...
Au lieu de considérer la population en entier, on peut considèrer seulement un sous-ensemble de P (une partie de P) sur lequel on va effectuer des observations ; ce sous-ensemble est appelé échantillon. Le nombre d'individus qui le constituent est la taille de cet échantillon.
Exemple : pour effectuer un sondage de popularité d'une personnalité politique ou d'un footballeur, les médias interrogent un nombre restreint de personnes censées représenter toute la population.
L'échantillonnage peut être subdivisé, selon la méthode de sélection de l'échantillon, en deux types :
- probabiliste : la sélection est aléatoire (se fait au hasard), c'est-à-dire que chaque individu a les mêmes chances qu'un autre d'être pris dans l'échantillon. C'est la méthode d'échantillonnage la plus facile à appliquer et la plus couramment utilisée.
Exemple : dans une grande usine de 5 000 employés, on veut mener une enquête sur la qualité des plats servis à la cantine. Pour sélectionner un échantillon de 100 employés, on attribue un numéro à chaque individu de 1 à 5 000, on utilise ensuite une table de numéros engendrés au hasard dans cet intervalle (voir Générateur de nombres aléatoires).
- non probabiliste : dans ce cas on est contraint de choisir arbitrairement les unités qui constituent l'échantillon. Bien qu'il présente un certain nombre d'inconvénients, ce type d'échantillonnage est utile dans certaines situations, commee le domaine des sciences sociales ou les essais de produits pharmaceutiques.
Exemples : les 100 premiers clients qui entrent dans un magasin, les 10 personnes qui se présentent volontairement pour le test d'un nouveau médicament ...
L'erreur d'échantillonnage peut être estimée mathématiquement. C'est le degré de variation qui existe entre les estimations établies à partir des différents échantillons possibles. Si l'erreur est importante, on parle de biais. Dans ce cas, l'échantillon biaisé ne représente pas la population dont il est issu.
Les types de caractères
modifierUn caractère étudié peut être soit qualitatif, soit quantitatif (appelé aussi variable). On parle alors de modalités d'un caractère qualitatif et des valeurs d'une variable.
- Le caractère qualitatif :
C'est un caractère qui ne peut être ni mesuré ni repéré par un nombre. Les modalités du caractère qualitatif rangent les unités de la population étudiée en catégories. Tout individu appartient, sans ambiguïté, à une seule catégorie.
Exemple: le sexe, la couleur des cheveux, le pays d'origine ... - Le caractère quantitatif :
C'est un caractère qui peut être mesuré ou repéré par un nombre.
Exemple: la taille et le poids d'un individu, l'âge, le montant du salaire ...
La variable peut être de deux natures :- une variable discontinue ou discrète ne peut prendre que des valeurs isolées, souvent entières, dans l'intervalle où elle varie.
Exemple: le nombre d'enfants dans une famille (il n'y a pas de ½ enfant !), le nombre d'élèves dans une classe de CM1 ...
- une variable continue peut prendre n'importe quelle valeur dans l'intervalle.
Exemple: la taille, le poids, la température ...
- une variable discontinue ou discrète ne peut prendre que des valeurs isolées, souvent entières, dans l'intervalle où elle varie.
Les échelles de mesure
modifierPour chaque type de caractère il existe une échelle de mesure faisant appel à la notion de modalité pour un caractère qualitatif et à la notion de valeur pour un caractère quantitatif. À partir des notions d'ordre et de distance, on distingue quatre types d'échelles de mesure :
- Les échelles qualitatives :
- Un caractère est dit nominal lorsque les seules relations que l'on peut établir entre les différentes modalités sont des relations d'équivalence ou de différence. Une échelle nominale consiste à attribuer un numéro à des individus dans le but de les distinguer.
Exemple : numéro de sécurité sociale, code postal ... - Un caractère est dit ordinal lorsqu'en plus des relations d'équivalence on peut établir des relations d'ordre. L'ensemble des modalités peut être rangé en ordre croissant ou décroissant. Les différences entre deux rangs successifs ou les rapports n'ont pas de signification.
Exemple : mention obtenue au baccalauréat = {passable, bien, assez bien...}, type de revenu mensuel = {faible , moyen , élevé} ...
- Un caractère est dit nominal lorsque les seules relations que l'on peut établir entre les différentes modalités sont des relations d'équivalence ou de différence. Une échelle nominale consiste à attribuer un numéro à des individus dans le but de les distinguer.
- Les échelles quantitatives:
- Pour la variable d'intervalle, une notion de distance est définie en plus d'une relation d'ordre.
Exemple : température, latitude, longitude ...
Le rapport de deux intervalles est indépendant de l'unité de mesure et de l'origine (le zéro est arbitraire).
Exemple : on sait que la température est mesurée en degrés dans les échelles de Celsius (C) ou de Fahrenheit (F). Les origines des deux échelles ne coïncident pas puisque 0°C = 32°F. La formule de conversion est :
Observez les données suivantes :Mesure Température en °C Température en °F 1 5 41 2 10 50 3 15 59 Vous remarquez qu'entre les deux échelles, les rapports ne sont pas conservés :
En revanche, le rapport des différences reste constant :
- Pour la variable de rapport, le rapport entre deux valeurs a un sens. Il est indépendant de l'unité de mesure. Il existe une origine naturelle et absolue (le zéro a une signification précise, puisqu'il désigne l'absence du caractère considéré).
Exemple : vitesse, taille, poids ...
Les deux échelles de masses en grammes (g), ou en livres (lb) possèdent une origine absolue : 0 g = 0 lb. Les masses de trois objets sont donnés en g et en lb :Objet masses en g masses en lb 1 200 0,44 2 500 1,1 3 1000 2,2 Vous remarquez que même si on change d'échelle, les rapports entre les masses des objets (1) et (2) restent constants :
De même, les rapports des différences sont identiques. En d'autres termes, l'objet (3) reste 5 fois plus massif que l'objet (1), que leurs masses soient exprimées en g ou en lb.
- Pour la variable d'intervalle, une notion de distance est définie en plus d'une relation d'ordre.




Les séries statistiques univariées
modifierUne distribution statistique indique la présentation des individus selon la valeur du caractère. Dans ce qui suit, on va décrire et représenter des distributions à un caractère. On parle aussi de série statistique monodimensionnelle ou univariée.
Caractère qualitatif
modifier- Présentation sous forme de tableaux : On représente la distribution observée sous la forme d'un tableau statistique à deux colonnes ou à deux lignes, l'une indique la nomenclature, l'autre le nombre d'unités statistiques (l'effectif) de chaque modalité. Soit le nombre de modalités différentes : et le nombre d'éléments correspondants à chaque modalité. On obtient alors le tableau statistique suivant :



| Nomenclature (les modalités) | Nombre d'unités (l'effectif) | Fréquence |
|---|---|---|
| ... | ... | ... |
| ... | ... | ... |
| Total |











est l'effectif, ou la fréquence absolue, correspondant à la modalité du caractère étudié. La somme des effectifs, notée par , s'appelle l'effectif total.
On définit la fréquence relative par la proportion des individus qui présentent le caractère par rapport à l'effectif total. Cette fréquence peut-être exprimée par un nombre décimal (0,3) ou par un pourcentage (30%).
La somme des fréquences relatives est appelé fréquence totale :

Toute fréquence relative est comprise entre 0 et 1 ( ).

Exemple : le relevé des cas de tuberculose dans quelques hôpitaux tunisiens (source : Bulletin National Epidémiologique, 2004).
| Ville | Effectif | Fréquence |
|---|---|---|
| Ariana | 112 | 0,14 |
| Bizerte | 146 | 0,18 |
| Gabès | 54 | 0,07 |
| Tunis | 294 | 0,37 |
| Sfax | 158 | 0,20 |
| Siliana | 25 | 0,03 |
| Total | 789 | 1 |
- Présentation sous forme graphique : La présentation graphique des données permet de donner une image simple et claire qui facilite l'interprétation des résultats par un "coup d’œil". Les types de présentation les plus courants sont les diagrammes à barres (ou en tuyaux d'orgue) et les Diagrammes circulaires à secteurs (ou en "Camembert").
Exemple: le tableau précédant est repris avec une présentation graphique, en diagramme à barres (à gauche) ou en "Camembert" (à droite).

Caractère quantitatif
modifierAssociée à tout caractère quantitatif, une variable statistique peut être discrète ou continue. Nous allons donc étudier les deux cas :
- Caractère discret
- Présentation sous forme de tableaux : on représente les données sous forme de tableau statistique analogue à celui obtenu pour un caractère qualitatif. Soit le nombre de valeurs possibles du caractère étudié. Pour chaque valeur correspond le nombre d'individus possédant cette valeur du caractère (effectif). Par convention, les valeurs sont toujours rangées par ordre croissant.
Le tableau sera donc sous la forme :Valeur du caractère Nombre d'unités (l'effectif) Fréquence ... ... ... ... ... ... Total Exemple : familles selon le nombre d'enfants âgés de 0 à 18 ans, en France (source : INSEE - Recensement de la population, 1999 [1])
Nombre d'enfants Nombre de familles Fréquence 0 8 678 858 0,54 1 3 317 094 0,21 2 2 771 784 0,17 3 1 007 563 0,06 4 230 279 0,01 5 61 615 0,004 6 29 589 0,002 Total 16 096 782 1 - Présentation sous forme de graphique : la représentation graphique des fréquences (ou des effectifs) de la distribution statistique d'une variable discrète est du type diagramme en bâtons ou en tuyaux d'orgue. Le diagramme est constitué par des bâtons dont la longueur est proportionnelle aux fréquences correspondant aux variables représentées sur l'axe des abscisses. Si l'on joint les extrémités des bâtons, on obtient le polygone des fréquences.
Exemple : les données du tableau précédent sont représentées sur un graphe en bâtons.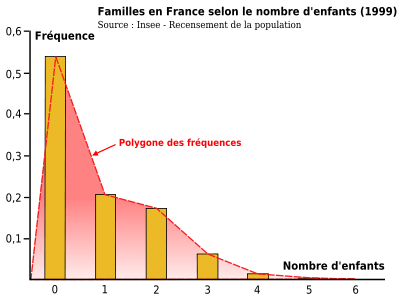
- Présentation sous forme de tableaux : on représente les données sous forme de tableau statistique analogue à celui obtenu pour un caractère qualitatif. Soit le nombre de valeurs possibles du caractère étudié. Pour chaque valeur correspond le nombre d'individus possédant cette valeur du caractère (effectif). Par convention, les valeurs sont toujours rangées par ordre croissant.
- Caractère continu :
- Présentation sous forme de tableaux : pour construire un tableau statistique, il faut effectuer une réduction des données. Pour cela, il faut prendre la différence entre la plus grande et la plus petite des valeurs observées et la partager en classes. On désigne alors par "effectif" le nombre d'unités statistiques de chaque classe.
Le tableau statistique se présente sous la forme :Classe Effectif Centre Amplitude Fréquence ... ... ... ... ... ... ... ... ... ... Somme - - 1 Observons ce tableau :
- sont les intervalles ou classes ; est la borne inférieure de l'intervalle, est la borne supérieure de l'intervalle. Par convention, un intervalle de classe est fermé à gauche et ouvert à droite.
Exemple: l'intervalle de classe [0 ; 200[ est désigné par "les valeurs de 0 à moins de 200". C'est-à-dire que la valeur 200 ne sera pas intégrée dans cette classe.
- est le nombre d'observations tombant dans la même classe.
Exemple: le nombre d'employés ayant un salaire de 700 à moins de 1000 € est de 26.
- La valeur absolue de la différence entre et est appelée amplitude et notée .
- On appelle centre de classe, , la demi-somme des extrémités de l'intervalle .
Exemple: pour la classe [400 ; 500[, l'amplitude = 500 - 400 = 100. Le centre = (500 + 400)/2 = 450.
- Comme pour le caractère discret, on définit l'effectif total , les fréquences qui correspondent à chaque classe et la fréquence totale.
Exemple: à compléter.
- sont les intervalles ou classes ; est la borne inférieure de l'intervalle, est la borne supérieure de l'intervalle. Par convention, un intervalle de classe est fermé à gauche et ouvert à droite.
- Présentation sous forme de graphique : la représentation graphique des fréquences / des effectifs d'une distribution statistique d'une variable continue s'appelle histogramme. La population d'une classe est représentée sous forme d'un rectangle de surface proportionnelle à sa fréquence / effectif.
- Lorsque les classes sont d'amplitudes égales, la hauteur du rectangle est proportionnelle à la fréquence / effectif.
- Lorsque les classes sont d'amplitudes inégales, il faut procéder au calcul des fréquences / effectifs corrigés pour assurer leur proportionnalité par rapport aux aires des rectangles correspondants. On prend généralement l'amplitude la plus faible comme valeur de référence.
- On peut tracer le polygone des fréquences / effectifs en joignant par des segments de droite les milieux des côtés supérieurs des rectangles de l'histogramme. Le polygone des fréquences permet ainsi d'évaluer visuellement le poids de chaque classe représenté par son centre.
- Choix du nombre de classes: le regroupement en classes présente une part de subjectivité. En effet, aucune loi mathématique ne permet de déterminer avec exactitude le nombre de classes à représenter. Il faut noter que ce nombre ne doit être ni trop grand, ni trop petit car tout regroupement entraîne inévitablement une perte d'information.
- Choix des valeurs limites des classes: il est souhaitable que les limites des classes comportent une décimale de plus que les valeurs des observations.
- Choix des étendues des classes: l'étendue d'une distribution est la différence entre la valeur maximale et la valeur minimale du caractère étudié. L'étendue élémentaire des classes (ou largeur des intervalles) est telle que :
Exemple: à compléter.
- Présentation sous forme de tableaux : pour construire un tableau statistique, il faut effectuer une réduction des données. Pour cela, il faut prendre la différence entre la plus grande et la plus petite des valeurs observées et la partager en classes. On désigne alors par "effectif" le nombre d'unités statistiques de chaque classe.




















![{\displaystyle k={\frac {5}{2}}\times {\sqrt[{4}]{n}}=2,5\times n^{0,25}\,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8489db7cea9c1bebb17f6162a936e19d35e95a43)


